Abstract
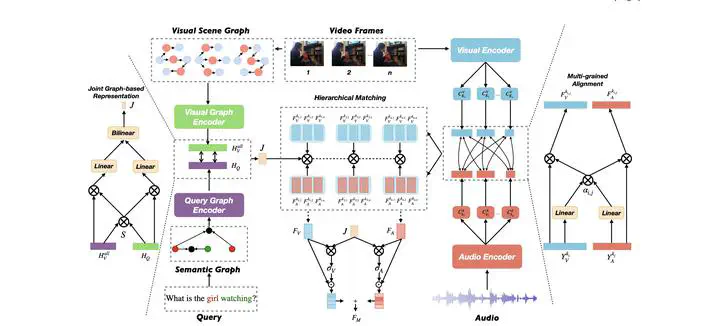
Video-language learning has attracted significant attention in the fields of multimedia, computer vision and natural language processing in recent years. One of the key challenges in this area is how to effectively integrate visual and linguistic information to enable machines to understand video content and query information. In this work, we leverage graph-based representations and multi-grained audio-visual alignment to address this challenge. First, our approach starts by transforming video and query inputs into visual-scene graphs and semantic role graphs using a visual-scene parser and semantic role labeler respectively. These graphs are then encoded using graph neural networks to obtain enriched representations and combined to obtain a video-query joint representation that enhances the semantic expressivity of the inputs. Second, to achieve accurate matching of relevant parts of audio and visual features, we propose a multi-grained alignment module that aligns the audio and visual features at multiple scales. This enables us to effectively fuse the audio and visual information in a way that is consistent with the semantic-level information captured by the graph-based representations. Experiments on five representative datasets collected for Video Retrieval and Video Question Answering tasks show that our approach outperforms the literature on several metrics. Our extensive ablation studies demonstrate the effectiveness of graph-based representation and multi-grained audio-visual alignment.